2023. 8. 8. 06:45ㆍ2023-2 KHUDA/ML 기초세션
이 게시물은 한빛미디어의 <혼자 공부하는 머신러닝 + 딥러닝>를 정리한 글입니다.
혼자 공부하는 머신러닝+딥러닝
혼자 공부하는 머신러닝 딥러닝, 무료 동영상 강의, 머신러닝+딥러닝 용어집을 다운로드 하세요. 포기하지 마세요! 독학으로 충분히 하실 수 있습니다. ‘때론 혼자, 때론 같이’ 하며 힘이 되겠
hongong.hanbit.co.kr
Chapter 02-1 훈련 세트와 테스트 세트
훈련 세트 - 모델을 훈련할 때 사용하는 데이터로, 보통 훈련 세트가 클수록 좋다. 따라서 테스트 세트를 제외한 모든 데이터를 사용한다.
테스트 세트 - 전체 데이터에서 20~30%를 보통 테스트 세트로 사용한다. 전체 데이터가 아주 크다면 1%만 사용해도 충분하다.
지도학습(Supervised learning) - 입력과 타깃 데이터를 전달하여 모델을 훈련하고 다음 새로운 데이터를 예측한다. Chapter 1에서 사용한 k-최근접 이웃이 지도 학습 알고리즘의 예이다.
비지도학습(Unsupervised learning) - 타깃 데이터 없이 입력 데이터만 주어진다. 따라서 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특징을 찾는 데 주로 활용한다.
Chapter 01-3에서 사용한 fish_data와 fish_target을 그대로 사용하도록 한다.
하나의 생선 데이터를 샘플(sample)이라고 부른다. 총 49개의 샘플 중 처음 35개를 훈련 세트로, 나머지 14개를 테스트 세트로 사용해 모델을 훈련해 보겠다.
#훈련 세트로 0부터 34번째 인덱스까지 사용
train_input = fish_data[:35]
train_target = fish_target[:35]
#테스트 세트로 35번째부터 마지막 인덱스까지 사
test_input = fish_data[35:]
test_target = fish_target[35:]
#테스트 세트로 평가하기
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn = kn.fit(train_input, train_target)
kn.score(test_input, test_target)
#-> 0.0, test sample에 있는 14개의 데이터를 다 맞추지 못함.
#[:35]로 나누었는데, 훈련 데이터는 도미 35마리, 테스트 데이터는 빙어 14마리의 정보가 입력되었기 때문!!!Chapter 01-3에서는 100%로 완벽했던 머신러닝 모델이 0%의 성능을 보이고 있다.
상식적으로 훈련 데이터와 테스트 데이터에서는 도미와 빙어가 골고루 섞여 있어야 한다. 하지만 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않아 샘플링이 한쪽으로 치우친 샘플링 편향(sampling bias)이 발생하였다.
따라서 넘파이(Numpy) 배열 라이브러리를 사용해 랜덤으로 골고루 훈련 세트와 데이터 세트를 나눠보겠다.
import numpy as np
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
print(input_arr)
#데이터 섞기
#인덱스가 담긴 배열을 넣어 원소를 선택하는 방식
np.random.seed(42)
index = np.arange(49) #0부터 48까지 1씩 증가하는 정수 배열을 만들어 줌.
np.random.shuffle(index)
#입력과 타겟이 쌍을 이루고 있는데, 따로 섞이게 되면 지도학습에서 정답을 제대로 못 주게 됨.
#쌍으로 섞이게 만들어야 함. -> index로 섞기!!!
#np.randomseed를 사용하는 이유 -> 재현성을 위해, 실제로 머신러닝 작업을 할 때 안 씀. 단지 교육용. 지도자와 학습자의 결과가 똑같이 나오게 하기 위해 사용하는 것.
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
훈련 세트와 테스트 세트에 도미와 빙어가 잘 섞여 있는지 산점도로 확인한다.

import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(test_input[:, 0], test_input[:, 1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()파란색이 훈련 세트, 주황색이 테스트 세트이다. 양쪽에 도미와 빙어가 모두 섞여 있다.
두 번째 머신러닝 프로그램
이전에 만든 kn 객체를 그대로 사용해 새로 만든 데이터로 훈련시킨다.
kn = kn.fit(train_input, train_target)
kn.score(test_input, test_target) #-> 1.0
kn.predict(test_input) #-> array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])이번엔 모델을 훈련에 참여하지 않은 샘플로 테스트했기 때문에 올바르게 평가되었다.
Chapter 02-2 데이터 전처리
이전에 썼던 방식과는 다르게 데이터를 랜덤하게 나눠볼 것이다.
import numpy as np
fish_data = np.column_stack((length, weight))
#column_stack은 주어진 두 배열을 나란히 세운 다음에 열로 붙여준다.
#특성을 열 방향으로 쌓아야 한다.
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
#concatenate는 붙여주는 역할
#np.ones((2, 3))
#-> [[1,1,1],
# [1,1,1]]
#np.full((2, 3), 9)
#-> [[9, 9, 9],
# [9, 9, 9]]
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target, random_state=42)
#stratify 매개변수에 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나눈다.
#훈련 데이터가 작거나 특정 클래스의 샘플 개수가 적을 때 특히 유용하다.
print(test_target)
#-> [0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]
수상한 도미 한 마리
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target) #-> 1.0
print(kn.predict([[25, 150]])) #-> [0.]k-최근접 이웃 모델로 학습한 결과 정확도는 100%지만, [[25, 150]]을 도미가 아닌 빙어라 예측하는 문제가 발생한다.
산점도를 통해 직접 확인해보겠다.

import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^') #marker 매개변수는 모양을 지정한다.
plt.xlabel('length')
plt.ylabel('weight')
plt.show()그래프를 보면 분명히 이 샘플은 도미 데이터에 더 가깝다. 왜 이 모델은 빙어 데이터에 가갑다고 판단한 걸까?
[[25, 150]] 샘플에 가까운 다섯 개의 데이터는 다음과 같다.
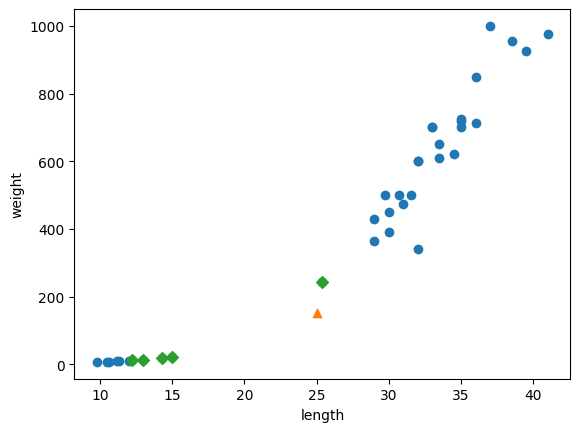
distances, indexes = kn.kneighbors([[25, 150]])
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
print(distances) #-> [[ 92.00086956 130.48375378 130.73859415 138.32150953 138.39320793]]예측 결과와 마찬가지로 가장 가까운 이웃에 4개의 샘플이 빙어이다.
기준을 맞춰라
산점도를 살펴보면 그래프에 나타난 거리 비율이 이상하다. x축의 범위는 10~40, y축의 범위는 0~1000으로 스케일(scale)이 매우 다르다. 따라서 특성값을 일정한 기준으로 맞춰주는 데이터 전처리(Data preprocessing)을 진행한다.
가장 널리 사용하는 전처리 방법 중 하나인 표준점수(Standard score)을 사용하겠다.
표준점수는 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지를 나타낸다.
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
print(mean, std) #-> [ 27.29722222 454.09722222] [ 9.98244253 323.29893931]
train_scaled = (train_input - mean) / std
test_scaled = (test_input - mean) / std브로드캐스팅(Broadcasting)은 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능이다.
아래 그래프는 앞서 표준편차로 변환하기 전의 산점도와 거의 동일하다. 크게 달라진 점은 x축과 y툭의 범위가 -1.5~1.5 사이로 바뀌었다는 것이다.

new = ([25, 150] - mean) / std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
전처리된 데이터로 다시 k-최근접 이웃 모델을 학습한다.
kn.fit(train_scaled, train_target)
kn.score(test_scaled, test_target)
print(kn.predict([new])) #-> [1.]
다시 new 샘플에 가장 가까운 샘플 5가지를 표시한 산점도는 다음과 같다.

distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()new 샘플에서 가장 가까운 샘플은 모두 도미이다.
—> 특성값의 스케일에 민감하지 않고 안정적인 예측을 할 수 있는 모델을 만들었다!
'2023-2 KHUDA > ML 기초세션' 카테고리의 다른 글
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 04-1 로지스틱 회귀 (0) | 2023.08.15 |
|---|---|
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 03-3 특성 공학과 규제 (0) | 2023.08.08 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 03-2 선형회귀 (0) | 2023.08.08 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 03-1 k-최근접 이웃 회귀 (0) | 2023.08.08 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 01 나의 첫 머신러닝 (0) | 2023.08.08 |