2023. 8. 29. 10:24ㆍ2023-2 KHUDA/ML 기초세션

이 게시물은 한빛미디어의 <혼자 공부하는 머신러닝 + 딥러닝>를 정리한 글입니다.
혼자 공부하는 머신러닝+딥러닝
혼자 공부하는 머신러닝 딥러닝, 무료 동영상 강의, 머신러닝+딥러닝 용어집을 다운로드 하세요. 포기하지 마세요! 독학으로 충분히 하실 수 있습니다. ‘때론 혼자, 때론 같이’ 하며 힘이 되겠
hongong.hanbit.co.kr
차원과 차원 축소
과일 사진의 경우 10000개의 픽셀이 있기 때문에 10000개의 특성이 있는 셈이다. 머신러닝에서는 이 특성을 차원(dimension)이라고도 부른다. 이 차원을 줄일 수 있다면 저장 공간을 크게 절약할 수 있을 것이다. 이를 위해 비지도 학습 작업 중 하나인 차원 축소 알고리즘을 다루어 보겠다. 차원 축소는 데이터를 가장 잘 나타내는 일부 특성을 선택하여 데이터 크기를 줄이고 지도 학습 모델의 성능을 향상시킬 수 있는 방법이다. 샘플이 가지고 있는 많은 특징을 적은 개수의 특징으로 줄이면서 정보량 손실을 최소화 하면서 줄이는 것이 목적이다. 또한 줄어든 차원에서 다시 원본 차원으로 손실을 최대한 줄이면서 복원할 수도 있다.
주성분 분석 소개
주성분 분석(PCA)는 대표적인 차원 축소 알고리즘이다. 입력 x를 열벡터와의 내적을 통해 저차원으로 변환하는 W행렬을 찾는 알고리즘이다. 이때, 분산이 클수록 정보 손실이 적다고 가정하고, 분산이 가장 큰 축으로 변환한다.
PCA 클래스
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
pca 객체를 만들 때 n_components의 매개변수에 주성분의 개수를 지정해야 한다.
from sklearn.decomposition import PCA
pca = PCA(n_components=50)
pca.fit(fruits_2d)
pca 클래스가 찾은 주성분은 components_ 속성에 저장되어 있다.
print(pca.components_.shape)
# -> (50, 10000)
draw_fruits(pca.components_.reshape(-1, 100, 100))
이 주성분은 원본 데이터에서 가장 분산이 큰 방향을 순서대로 나타낸 것이다.
주성분을 찾았기 때문에 원본 데이터를 주성분에 투영하여 특성의 개수를 10000개에서 50개로 줄일 수 있다.
print(fruits_2d.shape)
# -> (300, 10000)
fruits_pca = pca.transform(fruits_2d)
print(fruits_pca.shape)
# -> (300, 50)이제 fruits_pca는 50개의 특성을 가진 데이터이다.
원본 데이터 재구성
fruits_inverse = pca.inverse_transform(fruits_pca)
print(fruits_inverse.shape)
# -> (300, 10000)pca.inverse_transform()을 통해 50개의 차원으로 축소한 데이터로 10000개의 특성을 복원하였다.
fruits_reconstruct = fruits_inverse.reshape(-1, 100, 100)
for start in [0, 100, 200]:
draw_fruits(fruits_reconstruct[start:start+100])
print("\n")


일부분 흐리고 번진 부분이 있지만 거의 모든 과일이 잘 복원되었다.
설명된 분산
주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값을 설명된 분산이라고 한다. pca 클래스의 explained_variance_ratio_ 에 각 주성분의 설명된 분산 비율이 기록되어 있다. 이 분산 비율을 모두 더하면 50개 주성분으로 표현하고 있는 총 분산 비용을 얻을 수 있다.
print(np.sum(pca.explained_variance_ratio_))
# -> 0.9215434347802431
plt.plot(pca.explained_variance_ratio_)
그래프를 보면 처음 10개의 주성분이 대부분의 분산을 표현하고 있다.
다른 알고리즘과 함께 사용하기
과일 사진 원본 데이터와 PCA로 축소한 데이터를 지도 학습에 적용해 보고 어떤 차이가 있는지 알아보자. 3개의 과일 사진을 분류해야 하기 때문에 간단히 로지스틱 회귀 모델을 사용한다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
target = np.array([0] * 100 + [1] * 100 + [2] * 100)
from sklearn.model_selection import cross_validate
scores = cross_validate(lr, fruits_2d, target)
print(np.mean(scores['test_score']))
# -> 0.9966666666666667
print(np.mean(scores['fit_time']))
# -> 2.246530818939209
scores = cross_validate(lr, fruits_pca, target)
print(np.mean(scores['test_score']))
# -> 1.0
print(np.mean(scores['fit_time']))
# -> 0.05494117736816406원본 데이터로 학습한 것과 비교했을 때, 50개의 특성만 사용했는데도 정확도가 100%이고 훈련 시간은 0.05초로 엄청 감소하였다. PCA로 훈련 데이터의 차원을 축소하면 저장 공간뿐만 아니라 머신러닝 모델의 훈련 속도도 높일 수 있다.
여기서는 주성분의 개수를 직접 지정하였다. 이 대신 원하는 설명된 분산의 비율을 입력해 지정된 비율에 도달할 때까지 자동으로 주성분을 찾도록 할 수 있다.
pca = PCA(n_components=0.5)
#주성분 분석을 통해 얻을 수 있는 설명된 분산의 값이 50% 보다 높도록 주성분 개수를 자동 조절
pca.fit(fruits_2d)
print(pca.n_components_)
# -> 2단 2개의 특성만으로 원본 데이터에 있는 분산의 50%를 표현할 수 있다.
이 모델로 원본 데이터를 변환해보자.
fruits_pca = pca.transform(fruits_2d)
print(fruits_pca.shape)
# -> (300, 2)
scores = cross_validate(lr, fruits_pca, target)
print(np.mean(scores['test_score']))
# -> 0.9933333333333334
print(np.mean(scores['fit_time']))
# -> 0.058849096298217772개의 특성만을 사용하였는데 99%의 정확도를 달성했다!!
이번에는 차원 축소된 데이터를 활용해 k-평균 알고리즘으로 클러스터를 찾아보자.
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_pca)
print(np.unique(km.labels_, return_counts=True))
# -> (array([0, 1, 2], dtype=int32), array([110, 99, 91]))chapter 6-2에서 원본 데이터를 사용했을 때와 거의 비슷한 결과가 나왔다.
for label in range(0, 3):
draw_fruits(fruits[km.labels_ == label])
print('\n')


chapter 6-2에서 찾은 클러스터와 비슷하게 파인애플 클러스터에 사과 몇 개가 들어가 있다.
훈련 데이터의 차원을 줄이면 시각화 부분에서 장점을 얻을 수 있다. 3개 이하로 차원을 줄이면 화면에 출력하기 비교적 쉽다.
for label in range(0, 3):
data = fruits_pca[km.labels_ == label]
plt.scatter(data[:, 0], data[:, 1])
plt.legend(['apple', 'banana', 'pineapple'])
plt.show()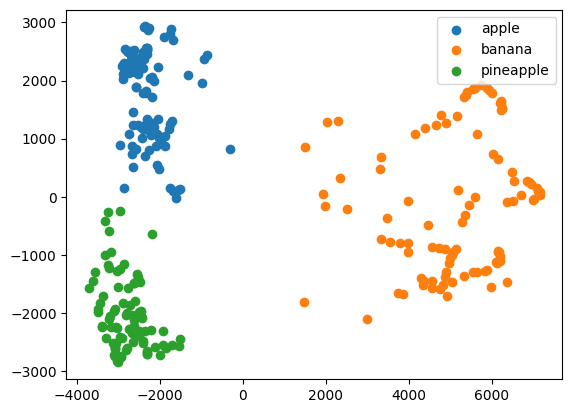
각 클러스터의 산점도가 잘 구분된다! 이 산점도를 보면 사과와 파인애플 클러스터의 경계가 가깝게 붙어있다. 파인애플 클러스터에서 혼동을 일으킨 이유를 알 것 같다.
'2023-2 KHUDA > ML 기초세션' 카테고리의 다른 글
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 06-2 k-평균 (0) | 2023.08.29 |
|---|---|
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 06-1 군집 알고리즘 (0) | 2023.08.29 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 05-3 트리의 앙상블 (0) | 2023.08.22 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 05-2 교차 검증과 그리드 서치 (1) | 2023.08.22 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 05-1 결정 트리 (1) | 2023.08.22 |