2023. 8. 22. 09:25ㆍ2023-2 KHUDA/ML 기초세션
이 게시물은 한빛미디어의 <혼자 공부하는 머신러닝 + 딥러닝>를 정리한 글입니다.
혼자 공부하는 머신러닝+딥러닝
혼자 공부하는 머신러닝 딥러닝, 무료 동영상 강의, 머신러닝+딥러닝 용어집을 다운로드 하세요. 포기하지 마세요! 독학으로 충분히 하실 수 있습니다. ‘때론 혼자, 때론 같이’ 하며 힘이 되겠
hongong.hanbit.co.kr
여러 특성값으로 로지스틱 회귀 모델을 적용해 와인의 종류를 구별해보자!
로지스틱 회귀로 와인 분류하기
우선 와인 데이터를 불러온다.
import pandas as pd
wine = pd.read_csv('http://bit.ly/wine_csv_data')
와인 데이터셋을 제대로 불러왔는지 head()메서드로 처음 5개의 샘플을 확인한다.
wine.head()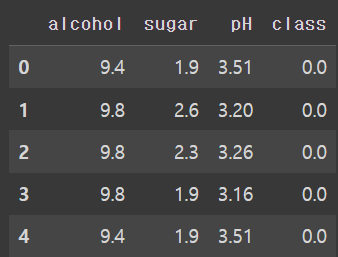
모델을 훈련하기 전에 데이터프레임의 각 열의 데이터 타입과 누락된 데이터가 있는지 확인하는 데 유용한 info()를 사용한다.
wine.info()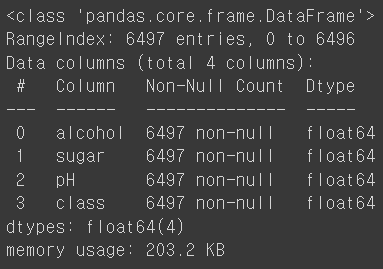
출력 결과를 보면 Non-Null Count가 모두 6497이므로 누락된 값은 없다.
describe() 메서드는 열에 대한 간략한 통계를 출력해준다.
wine.describe()
여기서 알코올 도수와 당도, PH의 값의 스케일이 다르다는 것을 알 수 있다.
사이킷런의 StandardScaler 클래스를 사용해 특성을 표준화하고, 로지스틱 회귀 모델을 훈련한다.
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42
)
print(train_input.shape, test_input.shape)
# -> (5197, 3) (1300, 3)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
# -> 0.7808350971714451
print(lr.score(test_scaled, test_target))
# -> 0.7776923076923077훈련 세트와 테스트 세트의 점수가 모두 낮은 걸로 보아 모델이 과소적합된 것 같다.
이 모델을 설명하기 위해 로지스틱 회귀가 학습한 계수와 절편을 출력하자.
print(lr.coef_, lr.intercept_)
# -> [[ 0.51270274 1.6733911 -0.68767781]] [1.81777902]왜 모델이 저런 계수 값을 학습했을까? 대부분 머신러닝 모델은 학습의 결과를 설명하기 어럽다.
결정 트리
결정 트리(Decision Tree) 모델은 스무고개와 같아 학습 이유를 설명하기 쉽다. 데이터를 잘 나눌 수 있는 질문을 찾는다면 계속 질문을 추가해서 분류 정확도를 높일 수 있다.
사이킷런의 DecisionTreeClassifier 클래스를 사용해 결정 트리 모델을 훈련하자.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
# -> 0.996921300750433
print(dt.score(test_scaled, test_target))
# -> 0.8592307692307692훈련 세트의 높은 점수에 비해 테스트 세트의 성능은 낮아 과대적합되었다.
이 모델을 plot_tree() 함수를 사용해 그림으로 표현해보자.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10, 7))
plot_tree(dt)
plt.show()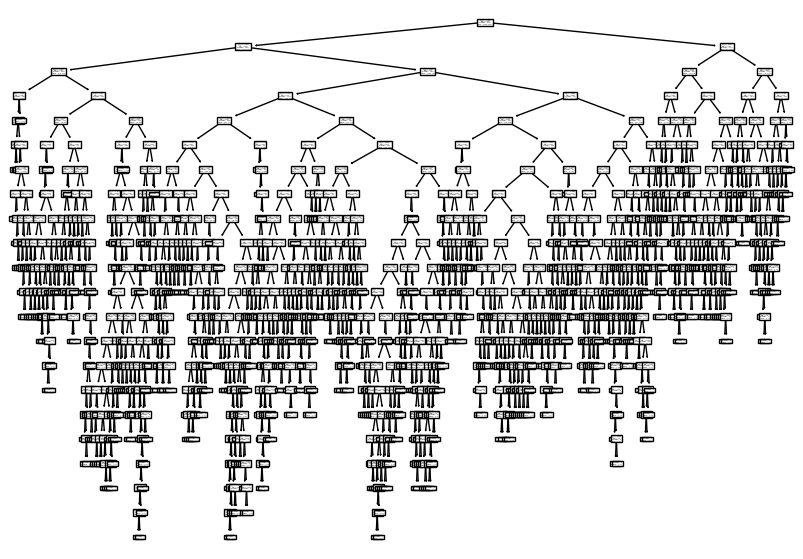
시작하는 맨 위의 노드를 루트 노드라 부르고 맨 아래 끝에 달린 노드를 리프 노드라고 한다.
너무 복잡하니 트리의 깊이를 제한해서 출력해보자. max_depth 매개변수를 n으로 두면 루트 노트를 제외하고 n개의 노드를 더 확장하여 그린다. 또 filled 매개변수에서 클래스에 맞게 노드의 색을 칠할 수 있다. feature_names 매개변수에는 특성의 이름을 전달할 수 있다.
plt.figure(figsize=(10, 7))
plot_tree(dt, max_depth=1, filled=True,
feature_names=['alcohol', 'sugar', 'pH'])
plt.show()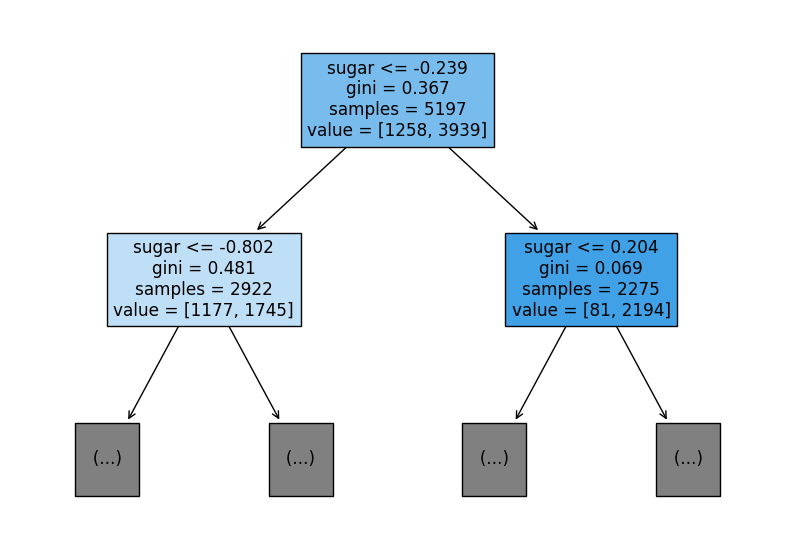
루트 노드는 당도(sugar)가 -0.239 이하인지 질문한다. 만약 어떤 샘플의 당도가 -0.239와 같거나 작으면 왼쪽 노드로 간다. 그렇지 않으면 오른쪽 노드로 간다. 루트 노드의 총 샘플 수는 5197개 인데, value의 음성 클래스는 레드 와인, 양성 클래스는 화이트 와인을 의미한다. 노드의 바탕 색깔을 보면 클래스마다 색깔을 부여하고, 어떤 클래스의 비율이 높아지면 점점 진한 색으로 표시한다는 것을 알 수 있다. 또한 결정 트리에서는 리프 노드에서 가장 많은 클래스가 예측 클래스가 된다.
그렇다면 gini는 무엇일까?
불순도
gini는 지니 불순도(gini impurity)를 의미한다. DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 gini이다. criterion 매개변수의 용도는 노드에서 데이터를 분할할 기준을 정하는 것이다. 지니 불순도를 사용해 어떻게 당도 -0.239를 계산했을까?

만약 어떤 노드의 두 클래스의 비율이 정확이 1/2씩이라면 지니 불순도는 0.5가 되어 클래스를 구별하지 못하는 최악의 상태가 된다. 또 노드에 하나의 클래스만 있다면 지니 불순도는 0이 되어 가장 작다. 이런 노드를 순수 노드라 한다.
결정 트리 모델은 부도 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킨다. 불순도 차이는 정보 이득(information gain)이라고 부른다.

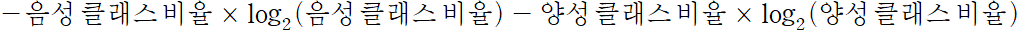
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
# -> 0.8454877814123533
print(dt.score(test_scaled, test_target))
# -> 0.8415384615384616훈련 세트의 성능은 낮아지고 테스트 세트의 성능은 거의 그대로지만, 과대 적합이 사라졌다.
plt.figure(figsize=(20, 15))
plot_tree(dt, filled=True,
feature_names=['alcohol', 'sugar', 'pH'])
plt.show()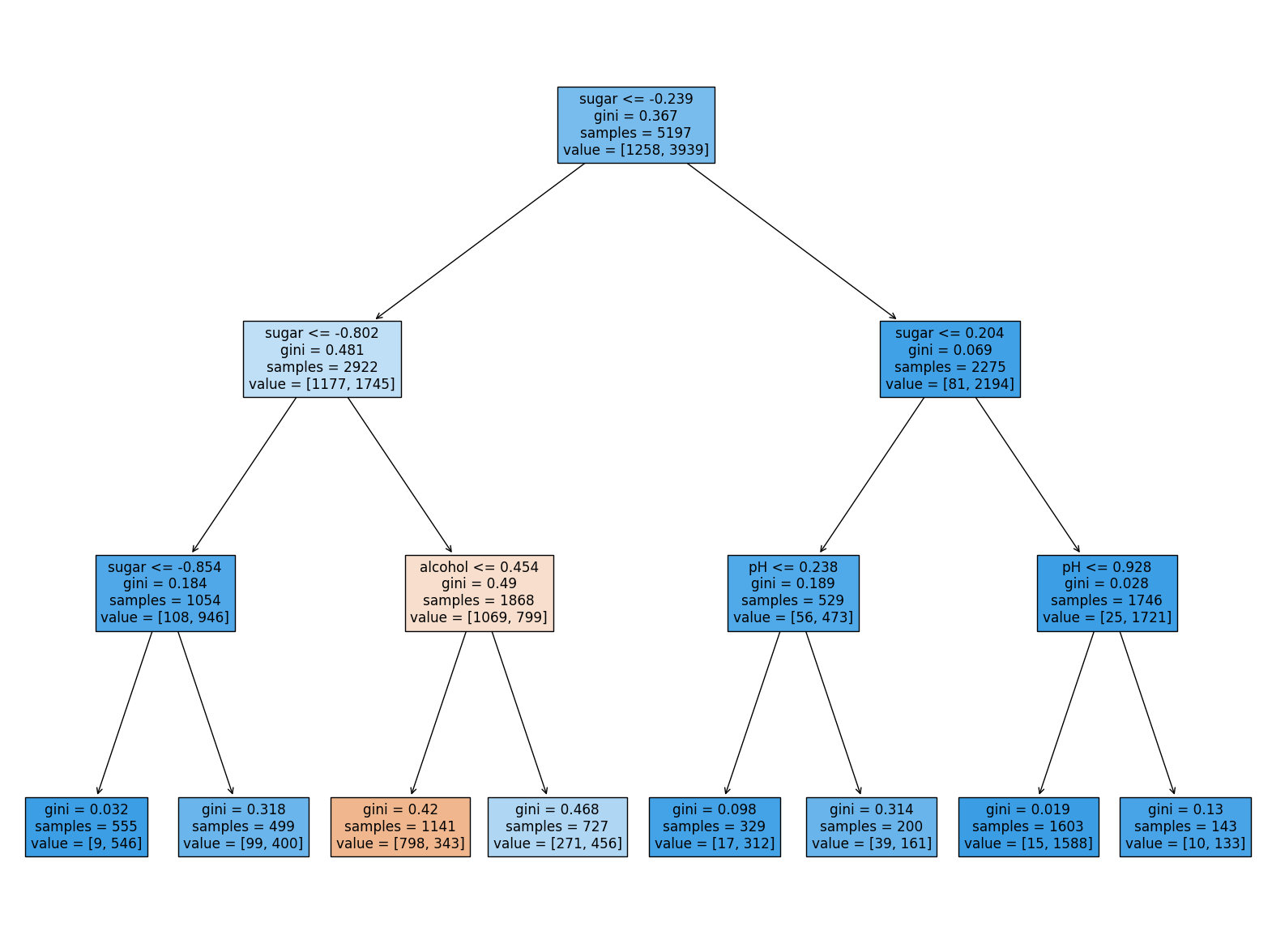
여기서 당도가 음수로 된 것이 이상하다. 샘플을 어떤 클래스 비율로 나누는지 계산할 때 특성값의 스케일이 계산에 영향을 미치지 않는다. 특성값의 스케일은 결정 트리 알고리즘에 아무런 영향을 미치지 않는다. 따라서 표준화 전처리를 할 필요가 없다. 전처리하기 전의 훈련 세트와 테스트 세트로 훈련해도 결과는 정확히 같다, 트리 그래프를 그려봐도 같은 트리이며, 특성값을 표준점수로 바꾸지 않아 이해하기 훨씬 쉽다.
이 트리의 루트 노드와 깊이 1에서 당도를 사용했기 때문에 아마도 당도가 가장 유용한 특성 중 하나일 것이다. 특성 중요도는 결정 트리 모델의 feature_importances_ 속성에 저장되어 있다.
print(dt.feature_importances_)
# -> [0.12345626 0.86862934 0.0079144 ]역시 두 번째 특성인 당도가 0.87 정도로 특성 중요도가 가장 높다. 특성 중요도는 각 노드의 정보 이득과 전체 샘플에 대한 비율을 곱한 후 특성별로 더하여 계산한다. 특성 중요도를 활용하면 결정 트리 모델을 특성 선택에 활용할 수 있다.
결정 트리는 많은 앙상블 학습 알고리즘의 기반이 된다. 앙상블 학습은 신경망과 함께 가장 높은 성능을 내기 때문에 인기가 높은 알고리즘이다. 다음 절에서는 결정 트리의 다양한 매개변수, 즉 하이퍼파라미터를 자동으로 찾기 위한 방법을 알아보고 앙상블 학습을 다루어 보겠다.
'2023-2 KHUDA > ML 기초세션' 카테고리의 다른 글
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 05-3 트리의 앙상블 (0) | 2023.08.22 |
|---|---|
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 05-2 교차 검증과 그리드 서치 (1) | 2023.08.22 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 04-2 확률적 경사 하강법 (0) | 2023.08.15 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 04-1 로지스틱 회귀 (0) | 2023.08.15 |
| [혼자 공부하는 머신러닝 + 딥러닝] Chapter 03-3 특성 공학과 규제 (0) | 2023.08.08 |